Pull-based Ingestion API
Introduced 3.0
Pull-based ingestion enables OpenSearch to ingest data from streaming sources such as Apache Kafka or Amazon Kinesis. Unlike traditional ingestion methods where clients actively push data to OpenSearch through REST APIs, pull-based ingestion allows OpenSearch to control the data flow by retrieving data directly from streaming sources. This approach provides native backpressure handling, helping prevent server overload during traffic spikes. Pull-based ingestion guarantees at-least-once ingestion semantics and uses external versioning to ensure data consistency.
Prerequisites
Before using pull-based ingestion, ensure that the following prerequisites are met:
- Install an ingestion plugin for your streaming source using the command
bin/opensearch-plugin install <plugin-name>. For more information, see Additional plugins. OpenSearch supports the following ingestion plugins:ingestion-kafkaingestion-kinesis(experimental)
- Configure pull-based ingestion during index creation. You cannot convert an existing push-based index to a pull-based one.
Creating an index for pull-based ingestion
To ingest data from a streaming source, first create an index with pull-based ingestion settings. The following request creates an index that pulls data from a Kafka topic in the segment replication mode. For other available modes, see Ingestion modes:
PUT /my-index
{
"settings": {
"ingestion_source": {
"type": "kafka",
"pointer.init.reset": "earliest",
"param": {
"topic": "test",
"bootstrap_servers": "localhost:49353"
}
},
"index.number_of_shards": 1,
"index.number_of_replicas": 1,
"index": {
"replication.type": "SEGMENT"
}
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
Ingestion source settings
The ingestion_source settings control how OpenSearch pulls data from the streaming source. A poll is an operation in which OpenSearch actively requests a batch of data from the streaming source. The following table lists all settings that ingestion_source supports.
Dynamic settings can be updated using the Update Settings API without restarting the ingestion process. Static settings cannot be changed after index creation. For more information about static and dynamic settings, see Configuring OpenSearch.
| Setting | Dynamic | Description |
|---|---|---|
type | No | The streaming source type. Required. Valid values are kafka or kinesis. |
pointer.init.reset | No | Determines the stream location from which to start reading. Optional. Valid values are earliest, latest, reset_by_offset, reset_by_timestamp, or none. See Stream position. |
pointer.init.reset.value | No | Required only for reset_by_offset or reset_by_timestamp. Specifies the offset value or timestamp in milliseconds. See Stream position. |
error_strategy | Yes | How to handle failed messages. Optional. Valid values are DROP (failed messages are skipped and ingestion continues) and BLOCK (when a message fails, ingestion stops). Default is DROP. |
poll.max_batch_size | Yes | The maximum number of records to retrieve in each poll operation. Optional. |
poll.timeout | Yes | The maximum time to wait for data in each poll operation. Optional. |
num_processor_threads | No | The number of threads for processing ingested data. Optional. Default is 1. |
internal_queue_size | No | The size of the internal blocking queue for advanced tuning. Valid values are from 1 to 100,000, inclusive. Optional. Default is 100. |
all_active | No | Whether to enable the all-active ingestion mode. Cannot be enabled for indexes that use segment replication mode. Default is false. See Ingestion modes. |
pointer_based_lag_update_interval | No | The interval at which pointer-based lag is calculated. Accepts time units. Default is 10s. Setting this value to 0 disables pointer-based lag calculation. |
warmup.timeout | Yes | The maximum amount of time to wait for the shard to catch up with the streaming source during the warmup phase after node restart or shard relocation. Shards will not serve queries until warmup completes or times out. Accepts time units. Optional. Default is -1 (disabled). |
warmup.lag_threshold | Yes | The acceptable pointer-based lag threshold for warmup completion. Warmup completes when the lag is at or below this value. A value of 0 means that the shard is synchronized with the source. Optional. Default is 100. |
mapper_type | No | Defines the mapper for the input message format. Valid values are default and raw_payload. See Message format. |
param | Yes | Source-specific configuration parameters. Required. • The ingest-kafka plugin requires:- topic: The Kafka topic to consume from- bootstrap_servers: The Kafka server addressesOptionally, you can provide additional standard Kafka consumer parameters (such as fetch.min.bytes). These parameters are passed directly to the Kafka consumer. • The ingest-kinesis plugin requires:- stream: The Kinesis stream name- region: The AWS Region- access_key: The AWS access key- secret_key: The AWS secret keyOptionally, you can provide an endpoint_override. |
Other settings
Pull-based ingestion supports the following OpenSearch settings.
| Setting | Dynamic | Description |
|---|---|---|
index.periodic_flush_interval | Yes | The interval at which OpenSearch triggers a flush operation. Default for pull-based ingestion indexes is 10m. See Index settings. |
Ingestion modes
Pull-based ingestion supports the following modes.
Segment replication mode
In segment replication mode, the primary shards ingest events from a streaming source and index the documents. The pull-based index is configured to use segment replication to copy over the segment files from primary to replica shards, as shown in the following image.
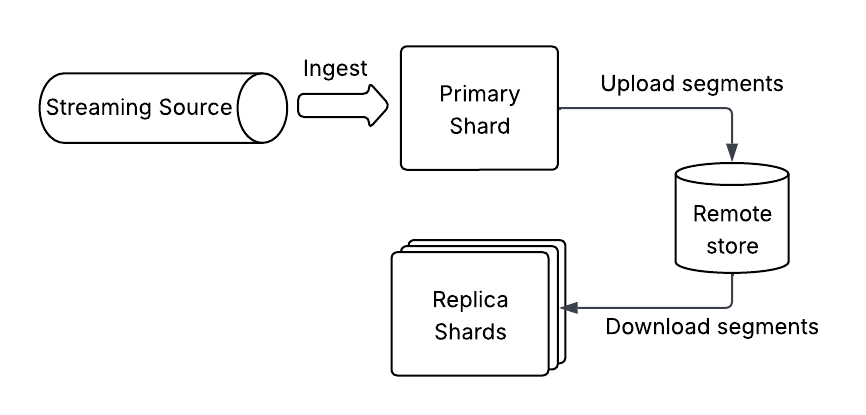
We recommend using this mode with remote-backed storage.
All-active mode
Enabling all-active mode allows both primary and replica shards to independently ingest and index events from the streaming source, as shown in the following image.
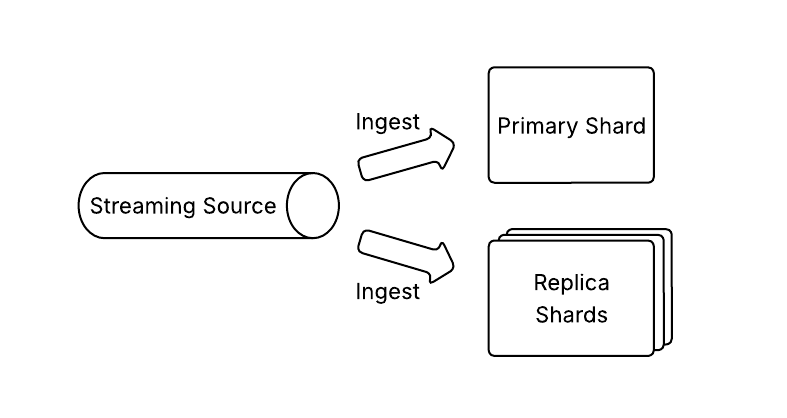
There is no replication or coordination between the shards, although replica shards may fetch segment files from the primary shard during bootstrapping if a local copy is unavailable. This mode is currently not supported with segment replication.
Stream position
When creating an index, you can specify where OpenSearch should start reading from the stream by configuring the pointer.init.reset and pointer.init.reset.value settings in the ingestion_source parameter. OpenSearch will resume reading from the last committed position for existing indexes.
The following table provides the valid pointer.init.reset values and their corresponding pointer.init.reset.value values.
pointer.init.reset | Starting ingestion point | pointer.init.reset.value |
|---|---|---|
earliest | The beginning of the stream | None |
latest | The current end of the stream | None |
reset_by_offset | A specific offset in the stream | A positive integer offset. Required. |
reset_by_timestamp | A specific point in time | A Unix timestamp in milliseconds. Required. For Kafka streams, defaults to Kafka’s auto.offset.reset policy if no messages are found for the given timestamp. |
none | The last committed position for existing indexes | None |
Stream partitioning
When using partitioned streams (such as Kafka topics or Kinesis shards), note the following relationships between stream partitions and OpenSearch shards:
- OpenSearch shards map one-to-one to stream partitions.
- The number of index shards must be greater than or equal to the number of stream partitions.
- Extra shards beyond the number of partitions remain empty.
- Documents must be sent to the same partition for successful updates.
When using pull-based ingestion, traditional REST API–based ingestion is disabled for the index.
Updating the error policy
You can use the Update Settings API to dynamically update the error policy by setting index.ingestion_source.error_strategy to either DROP or BLOCK.
The following example demonstrates how to update the error policy:
PUT /my-index/_settings
{
"index.ingestion_source.error_strategy": "DROP"
}response = client.indices.put_settings(
index = "my-index",
body = {
"index.ingestion_source.error_strategy": "DROP"
}
)Message format
To be correctly processed by OpenSearch, messages in the streaming source must have the following format:
{"_id":"1", "_version":"1", "_source":{"name": "alice", "age": 30}, "_op_type": "index"}
{"_id":"2", "_version":"2", "_source":{"name": "alice", "age": 30}, "_op_type": "delete"}
Each data unit in the streaming source (Kafka message or Kinesis record) must include the following fields that specify how to create or modify an OpenSearch document. This is the default format supported by pull-based ingestion.
| Field | Data type | Required | Description |
|---|---|---|---|
_id | String | No | A unique identifier for a document. If not provided, OpenSearch auto-generates an ID. Required for document updates or deletions. |
_version | Long | No | A document version number, which must be maintained externally. If provided, OpenSearch drops messages with versions earlier than the current document version. If not provided, no version checking occurs. |
_op_type | String | No | The operation to perform. Valid values are: - index: Creates a new document or updates an existing one.- create: Creates a new document in append mode. Note that this will not update existing documents. - delete: Soft deletes a document. |
_source | Object | Yes | The message payload containing the document data. |
We recommend using the document _id field to prevent duplicates, since pull-based ingestion provides at-least-once ingestion semantics. If your producer cannot guarantee event ordering, also set _version field to ensure data consistency.
Alternatively, pull-based ingestion supports indexing raw payloads in append-only mode without transformations. To enable this behavior, set index.ingestion_source.mapper_type to raw_payload. Note that in this mode, the index mappings must conform to the message structure because dynamic mapping is not supported. When using raw_payload, you must provide raw JSON objects exactly as they appear in the incoming data stream, as shown in the following example:
{"name": "alice", "age": 30}
{"name": "bob", "age": 30}
Pull-based ingestion metrics
Pull-based ingestion provides metrics that can be used to monitor the ingestion process. The polling_ingest_stats metric is currently supported and is available at the shard level.
The following table lists the available polling_ingest_stats metrics.
| Metric | Description |
|---|---|
message_processor_stats.total_processed_count | The total number of messages processed by the message processor. |
message_processor_stats.total_invalid_message_count | The number of invalid messages encountered. |
message_processor_stats.total_version_conflicts_count | The number of version conflicts due to which older version messages will be dropped. |
message_processor_stats.total_failed_count | The total number of failed messages, which error out during processing. |
message_processor_stats.total_failures_dropped_count | The total number of failed messages, which are dropped after exhausting retries. Note that messages are only dropped when the DROP error policy is used. |
message_processor_stats.total_processor_thread_interrupt_count | Indicates the number of thread interruptions on the processor thread. |
consumer_stats.total_polled_count | The total number of messages polled from the stream consumer. |
consumer_stats.total_consumer_error_count | The total number of fatal consumer read errors. |
consumer_stats.total_poller_message_failure_count | The total number of failed messages on the poller. |
consumer_stats.total_poller_message_dropped_count | The total number of failed messages on the poller that were dropped. |
consumer_stats.lag_in_millis | Lag in milliseconds, computed as the time elapsed since the last processed message timestamp. |
consumer_stats.pointer_based_lag | The Apache Kafka offset-based lag, calculated as the difference between the latest available offset and the current message offset. This metric applies only when Apache Kafka is used as the streaming source. |
To retrieve shard-level pull-based ingestion metrics, use the Nodes Stats API:
GET /_nodes/stats/indices?level=shards&prettyresponse = client.nodes.info(
metric = "indices",
node_id = "stats",
params = { "level": "shards", "pretty": "true" }
)Limitations
The following limitations apply when using pull-based ingestion:
- Ingest pipelines are not compatible with pull-based ingestion.
- Dynamic mapping is not supported.
- Index rollover is not supported.
- Operation listeners are not supported.